Here comes another tip for leveraging one of the most important inventions in the 20th century, the spreadsheet1.
Say you have a list of the number of GDPR fines and the country where they were issued, and you would want to know what the fine/population ratio is.
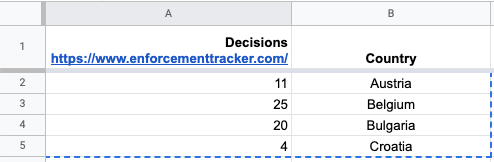
The easiest and quickest way be to go to Google it, and copy/paste the first table you find into a new Sheet. Then using the =VLOOKUP function to grab the population for each.
But I got curious if there would not be some more automated way to do this. And turns out there was, in 10 years ago Google Spreadsheets had more or less this exact function, =GoogleLookup("entity" ; "attribute") but it was deprecated in 2011 (probably for being too useful… or more likely abused somehow).
Luckily, there are still a few ways to import data into Google Sheets programatically, using =IMPORTXML, =IMPORTDATA, =IMPORTHTML and some third-party solutions like =IMPORTWEB.
Now, when we have a way to import data, we need to find a good place to import the data from. Preferably a place which has all kinds of data, so we can reuse what we learn in this case to programatically fetch more complex data next time. Wikipedia seems like a good candidate, and it turns out there is a project called Wikidata, which aims to provide the knowledge stored on Wikipedia in a more structured format.
Getting data out of Wikidata is not that straightforward though, to represent the data, they use a graph format which you can query using a language called SPARQL. They do a much better job at teaching in on their site, and I’d recommend starting with this tutorial if you are interested.
After you have figured out your SPARQL query you can import it directly into Google Docs by copying the query URL and giving it to =IMPORTXML, and then pass it a XPATH to extract
The full =IMPORTXML command will look something like this
=IMPORTXML("https://query.wikidata.org/sparql?query=%23%20defaultView%3ABubbleChart%0ASELECT%20DISTINCT%20%3FcountryLabel%20%3Fpopulation%0A%7B%0A%20%20%3Fcountry%20wdt%3AP31%20wd%3AQ6256%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20wdt%3AP1082%20%3Fpopulation%20.%0A%20%20SERVICE%20wikibase%3Alabel%20%7B%20bd%3AserviceParam%20wikibase%3Alanguage%20%22en%22%20%7D%0A%7D%0AGROUP%20BY%20%3Fpopulation%20%3FcountryLabel%0AORDER%20BY%20DESC(%3Fpopulation)","/*/*/*[name()='result']","utf8")`
Two important things to note about this. First, the SPARQL result is name-spaced. You can see it from the xmlns part in the beginning.
<?xml version='1.0' encoding='UTF-8'?>
<sparql xmlns='http://www.w3.org/2005/sparql-results#'>
This means you need to select that namespace before you can run queries like /*/*/result, but the =IMPORTXML command does not (as far as I know) allow you to do it. A workaround is to use Xpath functions which search all namespaces, like /*/*/*[name()='result']. 2
Another thing to consider is that the SPARQL response or specification gives no guarantees for which order the columns are. So, you might get back <binding name='countryLabel'> first or second within the result. This is annoying as for =VLOOKUP to work the key needs to be to the left of the value you are looking up.
A workaround I stumbled upon is to add a ORDER BY DESC population, that will cause the columns to be ordered as listed in the query.
-
My personal opinion but I bet someone else also agrees. Spreadsheets excel(pun) at leveraging what computers are best at. ↩︎
-
This caused quite some confusion for me, because because for example
xpather.comdoes not take into account the namespace, so even if it worked there it did not work in the google sheet. Better to instead use https://extendsclass.com/xpath-tester.html which does require the correct namespace (or a function which searches all namespaces). ↩︎